
Cogworks CTO, Marcin explains why performance testing is so important in a project and how we can apply best practice.
Innerworks is coming soon...
This blog was originally published on our previous Cogworks blog page. The Cogworks Blog is in the process of evolving into Innerworks, our new community-driven tech blog. With Innerworks, we aim to provide a space for collaboration, knowledge-sharing, and connection within the wider tech community. Watch this space for Innerworks updates, but don't worry - you'll still be able to access content from the original Cogworks Blog if you want.
In our shared pursuit to push the web to do more, we're running into a common problem, performance. Sites have more features than ever before. So much so, that many now struggle to achieve a high level of performance across a variety of network conditions and devices.
I gave a talk this year at Umbraco Spark on this topic and I'd like to share with you my thoughts on performance and testing.
Why Does Performance Matter?
Performance issues vary. At best, they create minor delays that briefly annoy your users. At worst, they make your site completely inaccessible and unresponsive to user input...or both.
We want users to interact with what we build, right? If it’s a blog, we want people (you) to read it. If it’s an e-commerce site, we want customers to buy things. Performance plays a major role in the success (or failure) of any online business.

#perfmatters
"Downtime is better for a B2C web service than slowness. Slowness makes you hate using the service. Downtime you just try again later." Lenny Rachitsky, Product Manager, Airbnb (Everts, 2016)
Performance is no longer something that is just “nice-to-have” in applications that we build and use. Nor is it a luxury when a site is running fast.
Performance doesn’t just mean speed, it can also mean resource consumption and user perception. It is a public picture of the brand, the company and therefore the creator. In a world where time (and money) matter most, we don't want ourselves...or our clients to lose.
Depending on your project goals, there may be a few areas where you may need to look at performance, such as:
- Retaining users.
- Improving conversions.
- User experience.
- “Savings”.
No matter what drives us or our project stakeholders to care more about performance, we still seem to underestimate the value of performance and performance testing.
Without testing (at this stage let’s skip if it’s an automated process integrated with our CI/CD pipeline i.e within Azure DevOps or manual process done by manual testers) we can’t even talk about performance!
Metrics are the key to understand what causes issues with our software or user experience and shows us why we are, or are not, using software to its full potential for a business.
Why are we not telling our customers…?
- ...with the next release, you’ll lose $450k per month because of the performance degradation of our newly delivered feature
- ...we’ve just caused your bounce rate to increase by 20%, congrats!”
- ...we don’t know if our website will handle this traffic, let’s see…
Language and communication is vital within a project, but as these examples show, they can sometimes be handled one sprint too late. The solution?
Why not make performance a feature?
What if we really care about it from the beginning?
Performance should be treated as a feature of an application and receive the same (or IMO much more) attention and care as all the other key features of the piece of software we’re building day by day.
The sooner we spend time attaching well-known established, on-the-market tools to help us in the area of gathering metrics and performing as many automated tests and reports as possible, the sooner we’ll feel relieved and confident about what we deliver.
Metrics can only take us so far. We're not always able to know if we'll break our software or attach a performance degradation within the next piece of code we move into the develop branch. However, popular approaches such as TDD (Test Driven Development) and BDD (Behaviour Driven Development) can go a long way. I'm strongly in favour of PDD (Performance Driven Development), but there is nothing to stop us from combining two or three methods.
Begin with metrics
If we can’t measure, we can’t improve.
In order to measure, we must know what data to pay attention to. In the case of performance this is execution times, bottlenecks, long-running operations, most “popular” operations, hot paths, load times, feel times, user behaviours, TTFB, time to interact, amount of data consumed, amount of memory allocated and so on…
The data is out there to help us understand and stop guessing! This is the first step for more caviar in our technical involvement within the project build process.
It all sounds complicated...but as developers and technical people, we can be pragmatic by setting up a step-by-step process to ensure performance is made simple. Perhaps if we can measure the most problematic and “stressed” area of an app from the start, we can be more efficient and avoid those extra costs involved in creating unnecessarily long insurance policies? If we know what we’re measuring, we can generate a concise and project-specific document that is solution-focused.
Continue with metrics
It’s just as important to continuously measure performance as it is to address it at the start line. If we’re to treat performance as a feature, let’s work on it constantly. By breaking it down into “simple” steps, we can more easily treat performance as a vital cog in the project process. Throughout the project we should:
- Build.
- Measure.
- Optimise.
- Monitor.
Simple, right? These four principles can be integrated into the typical project cycle as shown below.
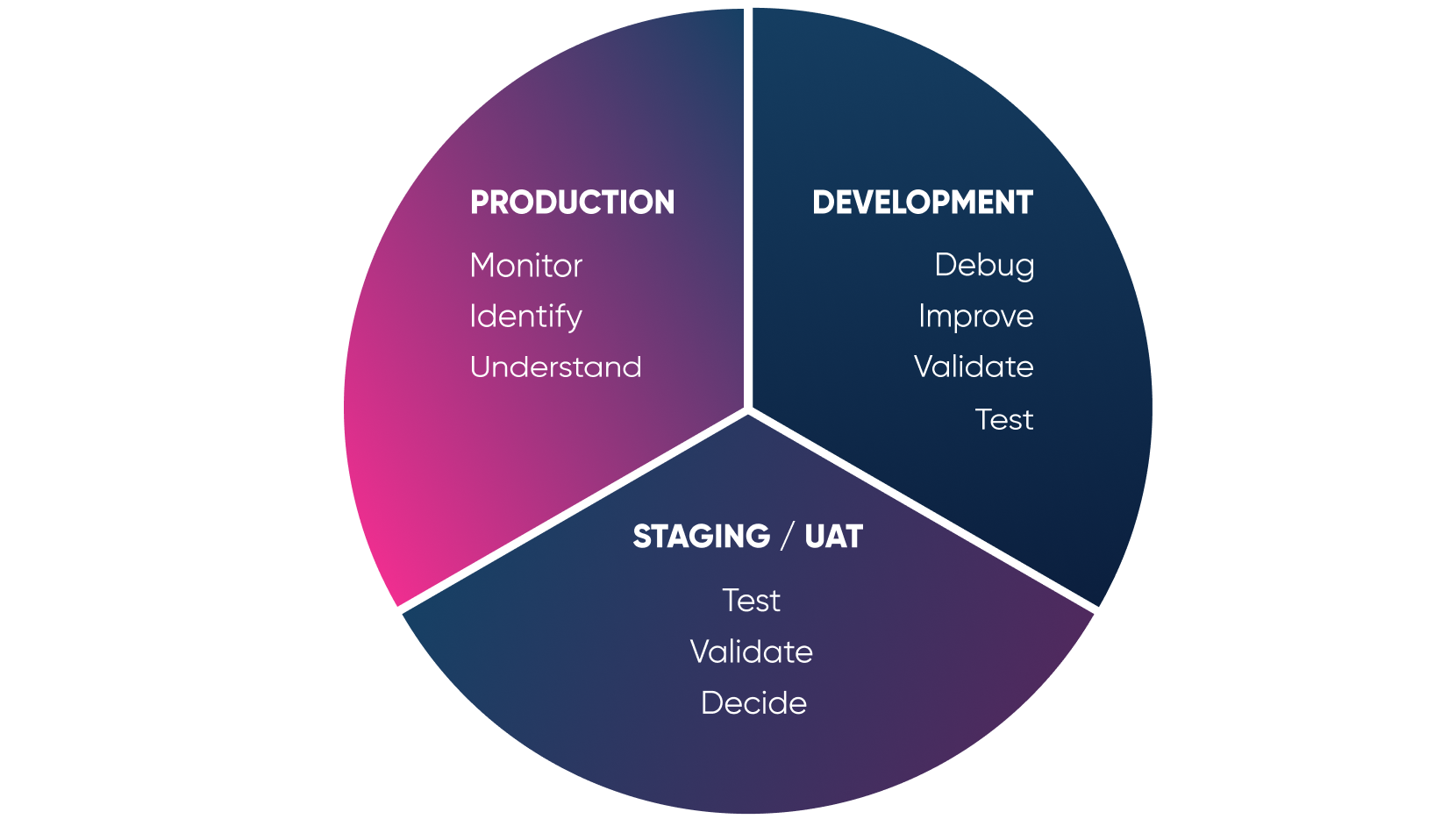
It’s impossible to discover all of the problems or potential issues with our application by only paying attention to this in the development phase.
Each stage has its own set of performance data which we should look at closely so that we can be ready to make improvements before the app is released into the wild! If something is not live yet...we can be ready. If it is live...we’re ready too because we know what performance metrics we need to look at.
Being pragmatic is key. Every project team should establish our own criteria for testing across these project stages. Only then is it worth implementing and executing if we know it will help...and not harm.
Unhelpfully, there are lots of testing myths to throw us off from doing it the right way. Like, codebases with “full test coverage” for example, we've all heard about this, but we don’t see it so often as it's extremely hard to accomplish! A lot of companies push this as a priority when really we should create our own criteria and best practice. When we start by doing this, the sooner this becomes a habit that we won’t be able to live without. The feeling that we are safe to "break stuff" is something we won’t want to give up easily...
The key part of the above chart is to understand the process behind it. Monitoring the development environment is useless in most of the cases, but we shouldn’t work with any kind of application which is not monitored in the production, right?
When it comes to decisions, it’s better to not act when we’re already fighting with fire, but when we have time to react. That’s what proper insurance should guarantee. We should feel safe and not focus too much on the unhandled consequences of our actions...
Why are we not treating performance seriously?
Can we ask ourselves this question? I mean, we’re all guilty of not doing it in every project in every possible case, right? Mea culpa, it took me too long to understand the real value of it and it’s why I’m writing this blog post - I hope it’ll help to open your eyes too :)
I’ve been thinking about my answer to this question and categorized the typical excuses and approaches seen in dev teams. ...I came up with four:
We think it’s too complicated.
We (or stakeholders) think it’s too expensive.
We don’t know HOW to do it…
- We simply don’t care 🤷♂️ (“this is fine”)
When it comes to points one, to three - it’s not the end of the world.
Hey, we can learn (hopefully we are already) and then demystify this subject. We can calculate the issues and convince people around us to invest their time and money. Simple!
Reason four is the most dangerous (and what’s funny...the most common!).
Many developers know about the consequences of their actions and steps. Many product owners know about issues and potential problems to which their products are faced. There are a lot of companies, teams and people that constantly observe and just simply...react to the issues in the "wild". I’ll let this popular meme illustrate my point ;)!

This is the area where it’s most challenging to convince people to switch their mindsets from reactive...to proactive!
How to get started!
Start simple. Describe the key functions of the application you want to improve. If it’s a web application, it’s worth bringing the studies of the performance issues discovered in the backend and frontend parts of the app.
Approximately 80% of the performance issues are usually in the frontend (FE) area, especially for the sites which are not heavily stressed or handling massive amounts of traffic. Less than 20% of the issues are on the backend (BE) layer. But when it comes to high performing applications, this is the area which requires more focus and optimization when it comes to the low-level response times or concurrent requests of high amount of users. Without the proper server, logic handling, the frontend might not have anything to serve and present.
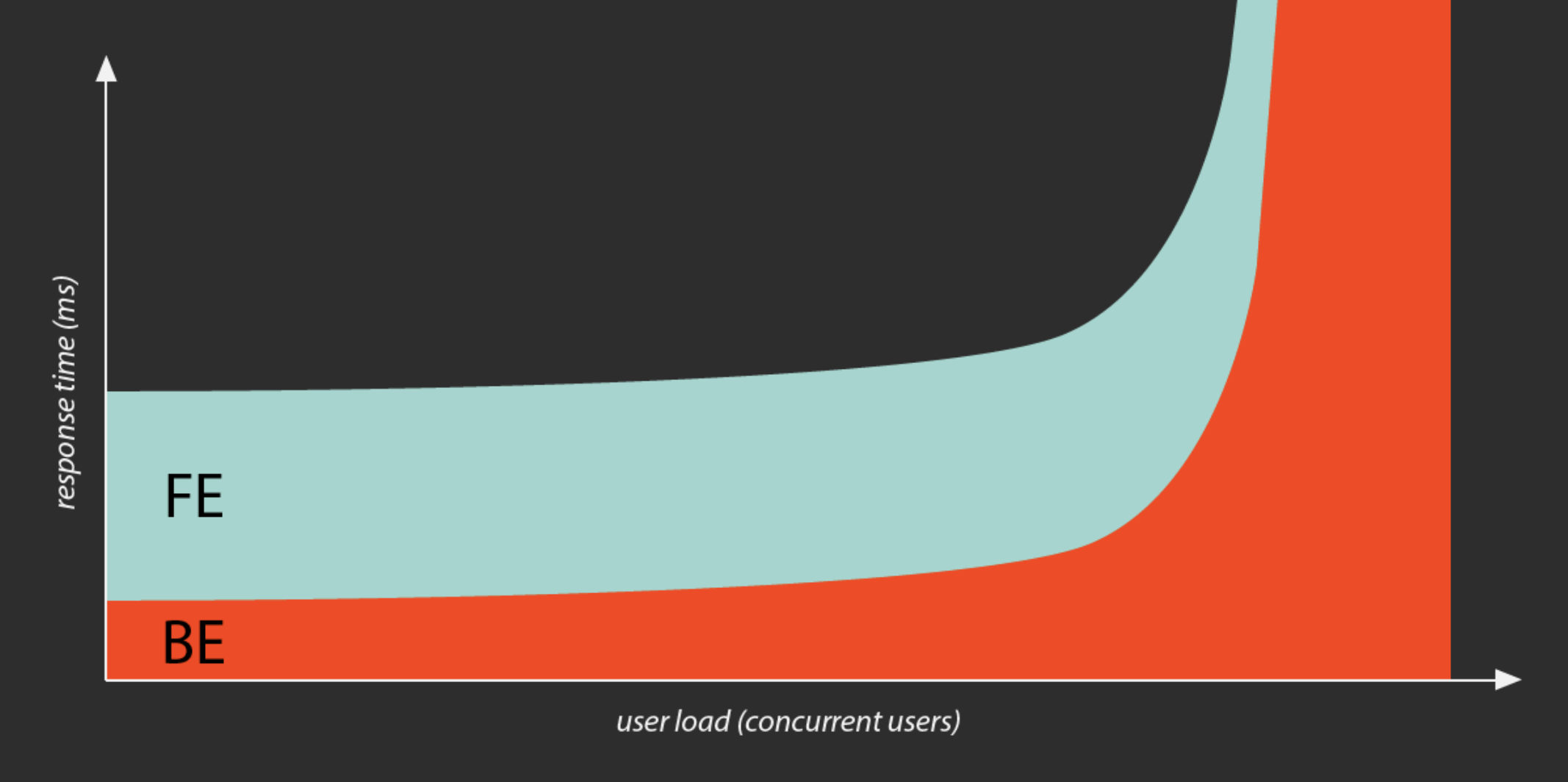
Use tools to measure.
With the above knowledge, we should go a step further. Depending on want to focus on, (FE or BE), we can use tools like:
- Lighthouse reports (in browser or manual/external/automated(!))
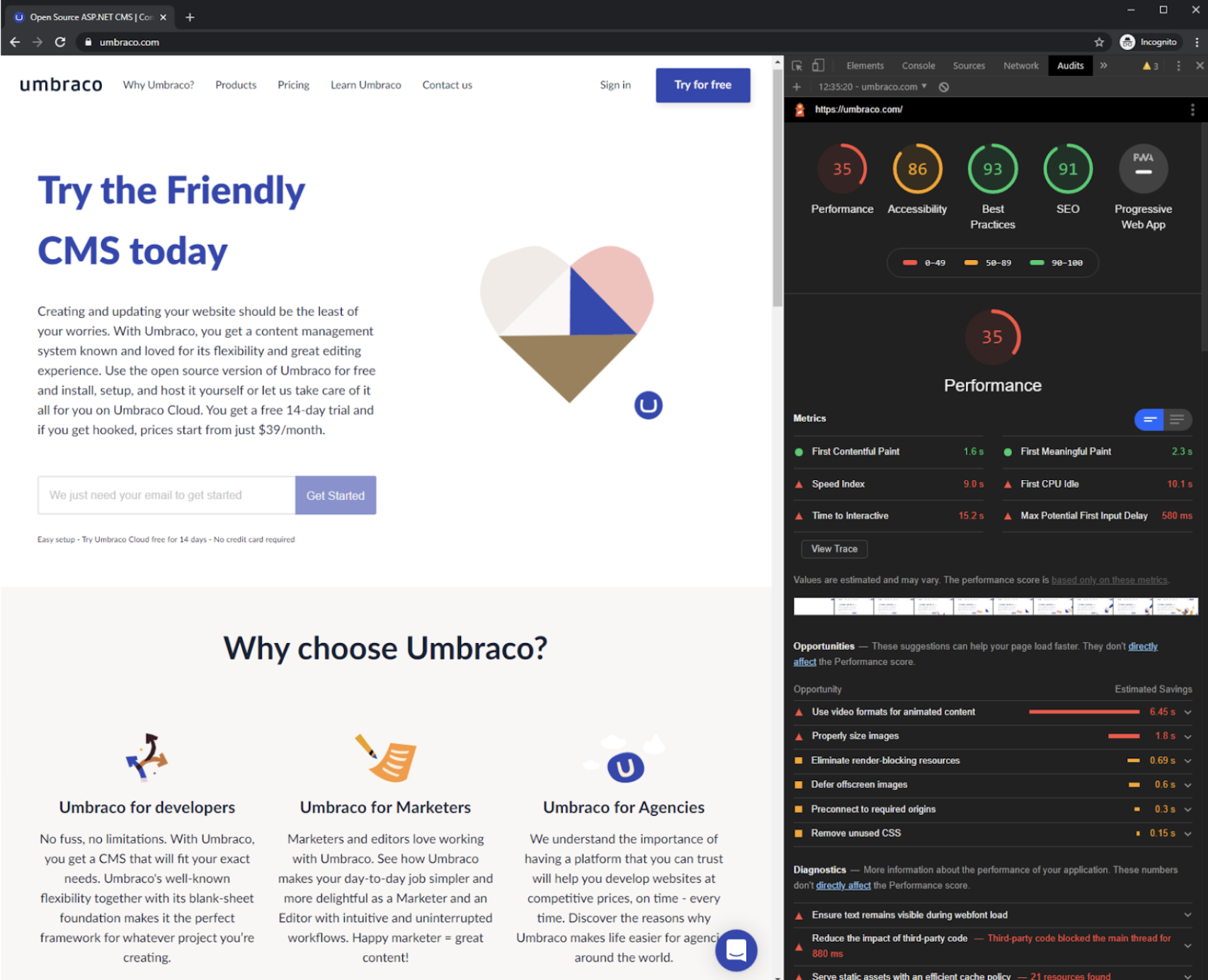
- MiniProfiler (.NET stack, built-in in Umbraco CMS)
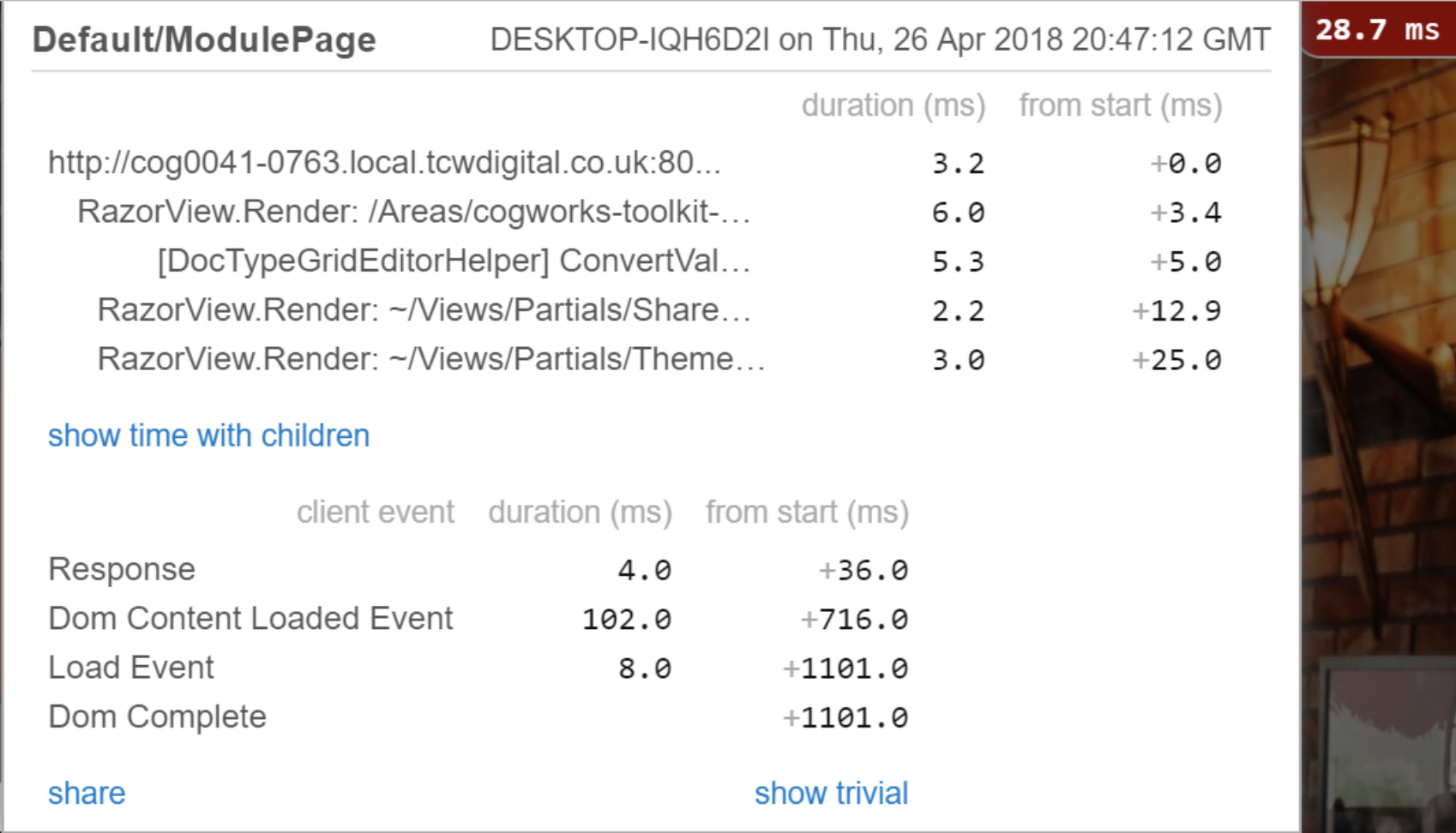
Tip: Spend some time finding the ‘red’ parts in the number of operations, times of execution or any other metrics which we’ll define as important at this stage.
Once we start to measure, let’s keep going!
- Improve your code - It doesn’t matter if it’s Javascript part of the app, SQL queries or any database-oriented languages/communication, or C# / Python or any other language hidden in the backed layer. Without changes and improvements here, we’re not able to fix the issues and compare the results (which we should already have at this first improvement round) in between project phases. It can be a logical change, but also a semantic or performance-oriented change suggested by analysers or tools built for the job! (E.g. ReSharper, Roslyn Analyzers).
- Measure (again!) - The tests should be performed again and results compared. It can be done manually (I know some teams who keep spreadsheets or markdown files within the repo in which they update results of the manual tests). Or, we can do this automatically with the help of Github Actions or Azure DevOps steps. We can use frameworks to get test reports too from xUnit/Selenium or something similar!
- Go deeper - Let’s not stop there. We can use tools like APM (Application Performance Monitoring/ Management), software like Dynatrace or Locust or attach some micro benchmarking practices in our codebase (e.g. using Benchmark.NET / NBench if we’re talking .NET here) and measure more insights within our methods and execution paths.
Tools like the above will deliver really high quality, meaningful results to manually process and possibly debug or fix to get back to step one or two in this algorithm. For the hardcore players, there are some tools to even jump into the memory allocations view e.g. PerfView, ANTS or Windbg, but if you know those tools you’re probably not reading this article in the first place ;)... - Automate - If we’re advanced enough and already see the potential of the steps we can achieve between point one and three of this list, we may need to simplify our life and get to work automating! All of the tools mentioned above have their API and attachment points which can be plugged into our normal pipelines used for the continuous integration and continuous deployment processes within our organisations. We can ensure that tests are performed at the correct stage and deliver the HTML or email reports to the stakeholders so we can prevent or stop deployments which are not meeting our expectations. Automatically, of course...
- Observe - This part is as important as any previously mentioned. Without proper data collected in real life (on production), we cannot confirm or deny that our steps have really improved the areas in which we wanted to have an impact. We can, of course, imitate and perform some load tests here as well, using k6 platform (previously LoadImpact) for example, but it’s not always possible to reflect the exact scenario of the app facing real users. What we really need is to have monitoring services that notify all responsible people to keep an eye on potential issues or errors caught by the code or server.
- Repeat - Over and over again. It’s a marathon, remember. It won’t get solved in a one-week sprint with a few hours attention. Be aware, and be prepared to treat performance as a feature. Then just watch how it makes your life...and code better!
- Have fun - Without fun, it may become boring! Why not check out companies such as Netflix to see what they are doing with their failures procedures? Why not set up a red team in your project or company and try to break your app? Hire or pay for a DDOS attack on your app and see if you’re prepared to handle it! You could even give the junior developer admin rights on your cloud management platform. Go wild!
Performance is no longer a luxury in software projects. Users today expect fast and stable websites that work! This means that performance can potentially be responsible for businesses success or failure...
Bad performance may cause the users to switch to something else, buy somewhere else or simply do something else instead of using the piece of software we created to catch their attention.
If we treat performance as a feature and focus on areas where we can start applying the first steps to improve performance and the testing around it. We can be pragmatic and do this without losing a lot of time, money and effort. It doesn’t need to be a NASA-like setup straight away.
Start simple and always measure. Measure everything possible. When you have enough data - think of how you can improve various areas based on the comparisons with data from the next versions of the code you produce.
Automate, observe and have fun along the way. In the end...learn, but not just from your mistakes.
Why not let us help you get started to apply best practice with an audit of your site or codebase? Get in touch below.
- Web Performance
- Testing
- Umbraco
- Applications
- Azure
- DevOps
- Metrics
- Optimise
- Measure
- Production
- Development
- Staging
- Lighthouse
- MiniProfiler
- Javascript
- Python
- Automation
- xUnit
- Selenium
- Dynatrace
- Algorithm
- PerfView
- HTML.
- umbraco gold partner