A reboot of the CogUmbracoExamineMediaIndexer package.
Innerworks is coming soon...
This blog was originally published on our previous Cogworks blog page. The Cogworks Blog is in the process of evolving into Innerworks, our new community-driven tech blog. With Innerworks, we aim to provide a space for collaboration, knowledge-sharing, and connection within the wider tech community. Watch this space for Innerworks updates, but don't worry - you'll still be able to access content from the original Cogworks Blog if you want.
When working with Examine, you will eventually have a customer requirement for indexing non-html content, i.e files in the media section. The default Examine offering is PDF indexer which, as the name suggests, can be used to index media files provided they are PDF format.
However, you may want to also index other file types like Word, Powerpoint or Excel, so what to do in this case? To address this issue, around 2012 I authored the CogUmbracoExamineMediaIndexer which to date has had 1600 downloads. The package targeted Umbraco v6.
I thought that the package could do with a refresh, and so The Cogworks is proud to present the reboot: Cogworks.ExamineFileIndexer.
This custom Examine indexer utilises Apache Tika. Apache Tika is a library that is used for document type detection and content extraction from various file formats. Internally, Tika uses existing various document parsers and document type detection techniques to detect and extract data.
Using Tika, one can develop a universal type detector and content extractor to extract both structured text, as well as metadata, from different types of documents, such as: spreadsheets, text documents, images, PDFs and even multimedia input formats to a certain extent.
Tika provides a single generic API for parsing different file formats. It uses existing specialised parser libraries for each document type.
As you can see from the Luke screenshot below, Tika will extract more than just the file content, it will also extract quite a lot of useful metadata:
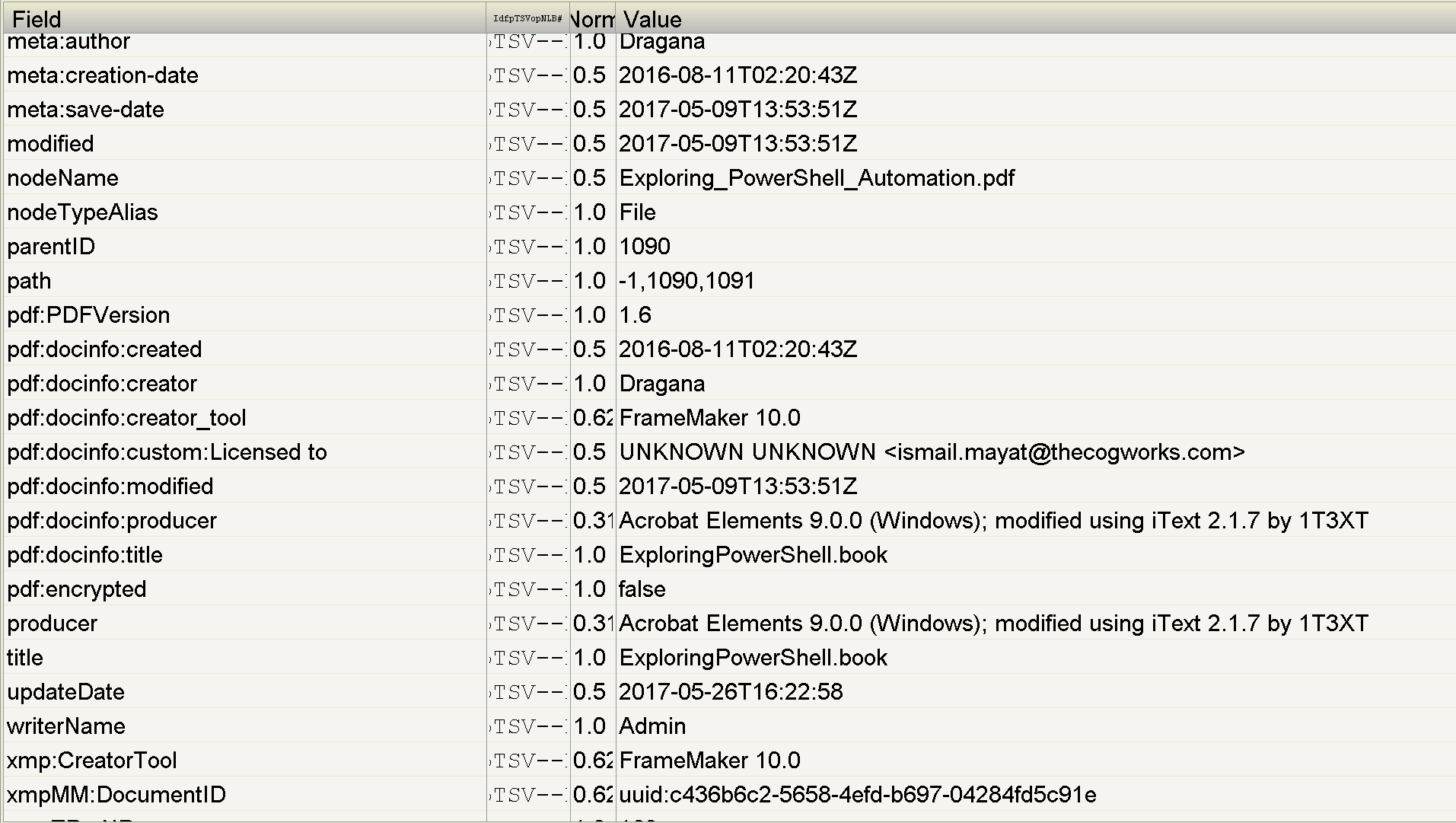
Tika internally also has a language detector class, so it can determine the language the document is written in. You can even do crazy things like detect phone numbers in the text.
More examples can be found on the Tika samples page (we may incorporate some of this other cool stuff in a later version), but if you really want to get into Tika there is a great book called Tika in action.
The package can be installed via nuget Install-Package Cogworks.ExamineFileIndexer
Upon installation ExamineIndex.config and ExamineSettings.config file will be updated. The following entries will be added:
ExamineIndex.config
<IndexSet SetName="MediaIndexSet" IndexPath="~/App_Data/TEMP/ExamineIndexes/MediaIndexSet">
<IndexAttributeFields>
<add Name="id" />
<add Name="nodeName" />
<add Name="updateDate" />
<add Name="writerName" />
<add Name="path" />
<add Name="nodeTypeAlias" />
<add Name="parentID" />
</IndexAttributeFields>
<IncludeNodeTypes>
<add Name="File" />
</IncludeNodeTypes>
</IndexSet>
And
ExamineSettings.config
Under ExamineIndexProviders/providers:
<add name="MediaIndexer" type="Cogworks.ExamineFileIndexer.UmbracoMediaFileIndexer, Cogworks.ExamineFileIndexer"
extensions=".pdf,.docx"
umbracoFileProperty="umbracoFile" />
Under ExamineSearchProviders/providers:
<add name="MediaSearcher" type="UmbracoExamine.UmbracoExamineSearcher, UmbracoExamine" indexSet="MediaIndexSet"
analyzer="Lucene.Net.Analysis.Standard.StandardAnalyzer, Lucene.Net" />
By default, the following file types will be indexed: pdf and docx. To add other file types to index you need to update ExamineSettings.config and add the extension to the extensions attribute:
<add name="MediaIndexer" type="Cogworks.ExamineFileIndexer.UmbracoMediaFileIndexer, Cogworks.ExamineFileIndexer"
extensions=".pdf,.docx"
umbracoFileProperty="umbracoFile" />
The package also supports virtual path providers. So, if you are storing media files in the cloud (e.g Azure, using the package UmbracoFileSystemProviders.Azure) then they will still be indexed.
You can install via nuget which is the preferred way, or you can install the Umbraco package on our.umbraco.org. Source code is available on github, so feel free to log any issues or fork and improve via pull request (contributions welcome, the VPP functionality was a contribution from Crumpled Dog made by Hendy Racher).
So go forth and index those files!
Did you know that media indexing is covered on the Umbraco Searching and Indexing course? To find an event near you take a look at the Umbraco course schedule page.

- Media Indexer Package
- Umbraco Package
- Cogworks Package